federate 설정
/federate는 하위 param 필드의 조건에 부합하는 메트릭을 리턴하는 path
##federation
- job_name: 'js_federation'
honor_labels: true #소스 서버에서 노출된 레이블을 덮어쓰지 않도록 true
metrics_path: '/federate'
scrape_interval: 5s
params:
'match[]':
- '{job=~".+"}'
- '{__name__=~"^job:.*"}'
static_configs:
- targets:
- '<public ip>:30052'
tls_config:
insecure_skip_verify: trueparams의 의미는 모든 job의 메트릭을 가져오는 것
타겟이 되는 프로메테우스는 오퍼레이터를 통해 설치
host에 해당하는 프로메테우스는 yaml파일을 통해 설치된 것으로 오퍼레이터의 경우 configmap에 접근하는 방법인 scrape_configs를 시크릿 타입으로 정의하여 적용하는 방법을 사용해 보았으나 구현에 실패하여 yaml로 진행
일정 부분 공통된 메트릭을 가지고 있으나, 오퍼레이터만 가져오는 정보 역시 존재
메트릭의 이해
메트릭은 2가지로 분류
시스템 메트릭 : 노드, 컨테이너의 cpu, memory 사용량 등의 기본적인 시스템 정보를 다루는 메트릭, cAdvisor을 통해 수집된 메트릭이 해당
kubelet의 cAdvisor를 통해 각 container에서 리소스 사용량을 수집
kubectl top 명령어를 쓸 수 있게 해주는 metric server도 kubelet에서 작동하며 수집, 취합하여 사용자에게 보여주거나, HPA에 사용할 수 있게 하는 역할
서비스 메트릭 : app의 모니터링을 위한 메트릭, 웹서버의 응답속도, 에러 빈도 등을 수집, kube state metrics가 해당, 문제가 생겼을 시 문제 정보를 alert에 넘겨 알림 발송
수집된 메트릭을 다시 취합해주는 파이프라인도 두 가지로 분류
리소스 메트릭 파이프라인 : 핵심 요소들에 대한 메트릭을 모니터링, 여기서 핵심 요소는 시스템 메트릭을 통해 수집된 정보들. kubelet, metrics-server가 이에 해당
풀 메트릭 파이프라인 : 사용자 정의 파이프라인, 외부 모니터링 시스템을 연계해서 이용, 시스템, 서비스 메트릭 모두 수용. 프로메테우스가 이에 해당
서비스 메트릭은 기존의 데이터가 아닌 메트릭을 가져오기 때문에 각 노드에 에이전트를 배치시켜야 함
그것이 node exporter라는 이름으로 프로메테우스에게 서비스 메트릭을 제공
node exporter는 하드웨어와 os 커널에 대한 정보, 즉 cpu, memory, network등의 정보를 수집

cAdvisor가 가져오는 정보 중에는 node 자체에 대한 정보를 출력하지 않음, 아래의 대시보드에서도 node 자체의 정보를 가져왔다기 보단 node의 내부 컨테이너들의 cpu 사용량의 합계의 값으로 가져옴
node exporter는 앞에 node_로 시작하는 노드 자체에 대한 메트릭을 수집
cAdvisor은 도커 엔진에 대한, node exporter는 호스트 자체에 대한 정보를 다룬다는 정보 확인, 좀더 명확한 차이를 원하기에 추가 조사 필요
node exporter의 사용 이유라기 보단 여러 exporter들을 쓰는 이유로 메트릭의 통일성을 주기위함이라는 주장이 존재
서로 다른 여러 클러스터에서 정보를 가져온다면 일관된 정보를 얻기 어려움
그렇기 때문에 동일한 exporter를 설치하여 메트릭의 통일성을 확보하는 것에 의의가 있음을 언급
여러 메트릭에서 정보를 가져오나 CPU, memory, network의 정보는 cAdvisor를 통해 수집
대시보드 구현

위부터 클러스터 들의 합, 1번 클러스터, 2번 클러스터의 수치를 나타냄
수집된 2번 클러스터의 메트릭에 접근하는 방법으로는 instance를 통한 방법과 정의된 prometheus의 이름(네임 스페이스), node 이름, 수집할 때 정한 job의 이름 등으로 접근 가능
각각 접근할 수 있는 정보는 다르기 때문에 사용하고자 하는 메트릭을 검색하여 그에 맞는 labels을 적용

예를 들어 위의 node_cpu_seconds_total의 메트릭은 위에서 말한 오퍼레이터가 제공하는 메트릭으로 yaml로 설치한 프로메테우스에서는 설정의 문제인지 수집이 불가능 했으며, 접근할 수 있는 경로로는 prometheus의 이름(네임 스페이스), instance에서의 노드 이름, 해당 정보를 제공하는 pod 등이 존재

해당 메트릭은 위에서 언급한 요청된(request) cpu core를 가져올 때 사용한 메트릭으로 해당 메트릭은 양 쪽의 프로메테우스가 모두 수집 가능했던 정보라 instance에 2번 클러스터의 pod IP와 1번 클러스터의 FQDN(정규화된 도메인)으로 접근이 가능한 것을 확인

container_cpu_usage_second는 yaml파일과 오퍼레이터로 설치한 프로메테우스 모두 가지고 있으며 id="/" 인자를 통해 cpu 현재 사용량을 출력
아직 인자에 대한 이해가 부족하여 id="/" 해당 인자가 정확히 어떤 역할을 하기에 구분해 주는 것 인지는 명확하지 않으며 추가적인 공부가 필요
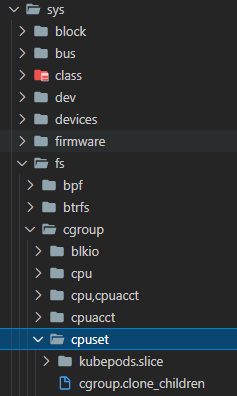
다른 메트릭이 가지는 id로는 id="/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod02b20d46_7fb1_4035_926f_7c0aa8f3b7cf.slice/docker-4f377de86b1f87d6d1248caa0f96f0f5a34f62723ef5b030f984d2fb746bd6a4.scope"
kubepods.slice는 검색 결과 cgroup 하위 경로로 확인


이미지가 없는 컨테이너를 제외한 값과 노드 내부에서 pod의 request로 설정되 수치들을 그래프화

각 노드 별로 사용중인 cpu양을 출력

pod는 kube-state-metrics를 통해 수집
현재 상태가 running인 pod를 가져와 총 pod의 갯수의 차이로 오작동 중인 pod의 갯수를 표출

complete된 파드들이 존재하여 3개의 차이가 존재

이와 같이 차이만큼의 오류를 시각적으로 표현
memory의 정보는 sum(container_memory_working_set_bytes{instance=~"etc", id="/"}) 인스턴스 기준으로 가져오며 host에 해당하는 정보는 각 노드의 이름을 instance인자로 받고 member에 해당하는 정보는 각 노드의 ip로 획득

역시 경로로 cgroup과 관련된 id를 사용

파드에 해당하는 정보들은 request의 수치를 사용하였고, 총합산 부분을 사용중인 메모리의 양을 사용하여 그래프를 나타냄

디스크 사용량 시각화
100 * (kubelet_volume_stats_used_bytes{} / kubelet_volume_stats_capacity_bytes{})
현재 사용중인 볼륨의 용량을 총 사용 가능한 볼륨의 용량으로 나누어 그래프화
현재 보여주는 지표들은 pv에 대한 지표들이며 2번 클러스터는 한 개의 pv만 가지고 있기 때문에 하나만 출력
네트워크로는 container_network_transmit_bytes_total 의 인자와 container_network_receive_bytes_total 인자 존재
각각 전송과 수신받는 네트워크를 의미

위에서의 id="/" 가 아닌 id!="/" 를 인자로 사용
The `id=”/”` is the lowest level cgroup namespace, which should report effectively system level metrics.
id=”/” 는 가장 낮은 레벨의 cgroup 네임스페이스이며, 효과적으로 시스템 단계의 메트릭을 보여줄 수 있다는 설명 존재
cgroup이 리소스의 관리를 맡고 있는 만큼 관련한 메트릭이 상당 수 존재
책의 14장에도 나오는 개념인 request와 limit과도 밀접한 관계가 있으며, 프로세스가 사용하는 리소스의 제한을 두거나 기록, 격리하는 역할을 수행
cgroup을 공부하던 중 의문점과 연관성을 가진 듯한 설명 발견

위에서의 대시보드와 다르게 id를 지정하지 않았을 cpu 코어의 사용량이 실제 사용량에 비해 비정상적으로 높음

최저 수준의 네임스페이스를 적용하면 실제 값과 근사한 값이 나오고 최저 수준의 네임스페이스를 제외하면2배가 훌쩍 넘는 양의 사용량을 출력
cgroup에서 cpu.shares이란 개념이 등장

해당 그림으로 어느정도 설명 되는 개념으로 A와 B가 존재하고, A하위로 A1, A2, B하위로 B1이 존재
A, B에 적힌 1024와 2048은 숫자만큼의 cpu를 점유한다가 아닌 총 cpu의 용량을 1024:2048 만큼의 비율로 점유할 수 있음을 뜻함
즉 3코어의 cpu가 있다면 A가 1코어, B가 2코어에 해당하는 만큼의 cpu를 점유하여 사용할 수 있음
그에 따라 하위 A들은 A가 점유한 1코어에 대해서 각각 512:1024의 비율로 점유할 수 있음을 뜻함
A1은 1/3 코어, A2는 2/3코어
여기서 A, B에 해당하는 것이 id=”/” 이고, A1, A2, B1에 해당하는 것이 id!=”/” 이라면 id를 정하지 않아 총 량을 구하게 될 경우 월등히 많은 cpu 사용량이 출력 될 수 있음을 납득
다른 의견으로는 위와 비슷하게도 같은 데이터가 중복 적용되어서 높게 측정되는 것

cpu/kubepods.slice/kubepods-besteffort.slice/kubepods-bustable-pod ~ . slice/docker- ~ .scope
위와 같은 경로로 설정되어 있는데 각 폴더마다 하위 폴더를 제외한 파일들은 동일한 구성으로 보유 중
id의 경로는 해당 폴더의 하위 폴더를 제외한 파일들을 의미하는 것으로 보임
즉 cpu 폴더의 파일은 노드 자체의 cpu 정보를 가지고, 하위 폴더는 파드, 컨테이너의 cpu 정보를 가지기 때문에 모두 더해지면 위와 같이 큰 수치가 되는 것으로 보임

'Kubernetes' 카테고리의 다른 글
| Kubesphere Tower Federation (0) | 2024.05.23 |
|---|---|
| Kubefed (0) | 2024.05.23 |
| Kubernetes EFK (0) | 2024.05.23 |
| Kubernetes Prometheus (0) | 2024.05.23 |
| Kubesphere Federation (0) | 2024.05.23 |



