StackLight
- Logging, Monitoring, Alerting을 포함하는 솔루션 패키지
- Kubesphere처럼 클러스터의 정보를 수정 ( edit ) 하는 것으로 설치 및 설정
- Helm chart를 통해 설치되며 해당 내용은 사용자에 의해 재정의 될 수 있음
- 재정의 영역은 아래 링크
- StackLight configuration parameters - Mirantis Container Cloud
버전은 릴리즈에 따라 상이하게 배포되며 Helm Bundle의 커스텀 리소스를 통해서 확인과 변경이 가능

특정 툴에 대해서 chartURL을 변경하는 것으로 버전 변경이 가능

Monitor component
- Ceph
- Ironic( Container Cloud bare-metal provider )
- K8s services:
- Calico
- etcd
- K8s cluster
- K8s container
- K8s deployment
- K8s node
- NGINX
- Node hardware and operating system
- PostgreSQL
- SMART disk ( 하드 디스크 드라이브의 실뢰성을 검사, 진단 )
- StackLight:
- Alertmanager
- Elasticsearch1.26.0 버전 이후로는 Opensearch
- Grafana
- Prometheus
- Prometheus Relay
- Pushgateway
- Salesforce notifier
- Telemeter
- SSL certificate
- MKE
- Docker/Swarm metrics ( through Telegraf )
- Built-in MKE metrics
StackLight Component
| component | description |
| Alerta | Alertmanager의 경고를 수신, 통합, 정제하여 시각화 |
| Alertmanager | Prometheus, group, 중복 제거, 통합 수신을 통해 app의 경고 알림 처리 |
| Elasticsearch curator | 인덱스를 관리하여 Elasticsearch의 데이터 유지, 데이터 보존 정책 관리 |
| Elasticsearch exporter | Elasticsearch의 내부 메트릭을 수집하는 Promethues exporter |
| Grafana | Prometheus를 지원하는 시각화 툴 |
| Database back ends | Alerta, Grafana를 위해 PostgreSQL사용 PostgreSQL은 노드 장애에 대해 모니터랑과 failover를 지원 위 SQL은 Patroni를 통해 버전관리 진행, 기능의 연속성을 유지 |
| Logging stack | 로그와 K8s 이벤트를 수집, 처리, 유지, 저장 management cluster에서는 기본값으로 활성화 managed cluster는 수동으로 활성화 Logging stack component
선택사항으로 Cerebro를 활성화 시켜서 사용 가능
|
| Metric collector | Telemetry( CPU, memory, number of alert, etc )를 수집하여 중앙 클라우드 스토리지로 전송하여 처리, 분석 management cluster에서 실행 |
| Prometheus | 엔드포인트를 자동으로 검색, 감시하여 메트릭 수집 기본 값으로 15일 혹은 15GB의 데이터를 저장 |
| Prometheus Blackbox Exporter | HTTP, HTTPS, DNS, TCP, ICMP를 통해 엔드포인트를 감시 |
| Prometheus-es-exporter | 쿼리를 통해 Elasticsearch에 대한 정보를 Prometheus 메트릭으로 표시 |
| Prometheus node exporter | 하드웨어, 운영 체제의 메트릭 수집 |
| Prometheus Relay | Prometheus에 프록시 레이어를 추가 레이어로 언더레이 결과를 병합해 데이터 누락을 방지 HA StackLight에서만 사용 가능 |
| Pushgateway | Pushgateway는 메트릭 캐시 스크랩시간이 부족해 노출이 불가능한 데이터에 대해서 일반적인 메트릭처럼 Prometheus에 노출 해당하는 데이터로는 ephemeral, batch job 등 |
| Salesforce notifier | Alertmanager를 통해 습득한 경고를 통해 Salesforce case를 생성 해당 경고가 해결되면 case를 closing 기본적으로 비활성화 |
| Salesforce reporter | Promethues에서 vCPU, vRam, vStorage의 데이터를 취합 Salesforce로 전송하여 고객 지원 목적으로 사용 기본적으로 비활성화 |
| Telegraf | Input, output plugin으로 구성 input은 시스템, 서비스, 서드파티 API에서 메트릭을 수집 output은 다양한 대상에서 메트릭을 노출 Telegraf agent
|
| Telemeter | Management cluster의 Grafana로 다중 클러스터를 모니터링 Promethues 페더레이션 분리된 Prometheus에서 메인 Prometheus가 정보를 수집할 수 있도록 페더레이션 푸시 방식을 사용하며, 가공, 익명화 진행 메트릭에 대한 안전 검증을 진행 메트릭은 로컬에 저장되었다가 메인에서 수집이 완료되면 삭제 클라이언트와 서버로 구분 클라이언트가 설치된 클러스터의 Prometheus에서 메트릭을 스크랩 서버가 설치된 클러스터로 전송
|
- 2.16.0 버전부터 Elasticsearch → Opensearch, Kibana → Opensearch dashboard로 전환
- Elasticsearch에 대한 라이센스의 변경으로 Opensearch로 전환
- 오픈소스인 Elasticsearch, Kibana에 대한 업데이트 중단
- 이후 버전은 자체 라이센스를 통해 제공
- Opensearch는 Elasticsearch의 브랜치로 오픈 소스
High availability
Managed cluster에 배포하기 전 HA 사용 여부를 지정
기본값으로 non-HA
Management, regional cluster에 StackLight를 실행하려면 HA mode로 사용
| Non-HA StackLight | HA StackLight | |
| Prometheus instance | 1 | 2 ( MCP에서는 3개의 서버를 사용 ) |
| Elasticsearch instance | 1 | 3 |
| PostgreSQL instance | 1 | 3 |
| PV 1개를 제공 장애가 발생하면 파드를 삭제 새 파드를 배포해 PV에 연결 |
Local volume provisioner를 통해 Local host storage를 제공 장애가 발생하면 트래픽을 Prometheus와 Elasticsearch가 실행 중인 다른 서버로 이전 |
StackLight가 배치될 노드는 cluster와 StackLight의 HA여부에 따라 결정
| Cluster | StackLight database mode | Target node |
| Management, regional | HA | 모든 K8s의 마스터 노드 |
| Managed | Non-HA | stacklight label이 붙은 노드 stacklight label이 없을 경우 모든 워커 노드에 배치 |
| HA | 3개 이상의 stacklight label을 가진 노드가 필요 모든 stacklight label이 붙은 노드 |
MCP에서의 Prometheus HA diagram

3개의 Prometheus를 운용
각각 독립적으로 데이터를 수집, Alertmanager로 중복 제거
각 Prometheus는 동일한 endpoint를 수집하기에 서로 대체가 가능
Prometheus 중 하나가 오류를 일으켜도 다른 Prometheus가 가용성을 유지
InfluxDB로 오류에 따른 대응을 진행, 정기적인 오류일 경우 재시도 횟수를 줄임
MCP에서의 Metric 수집 과정

MCP에서의 구성도
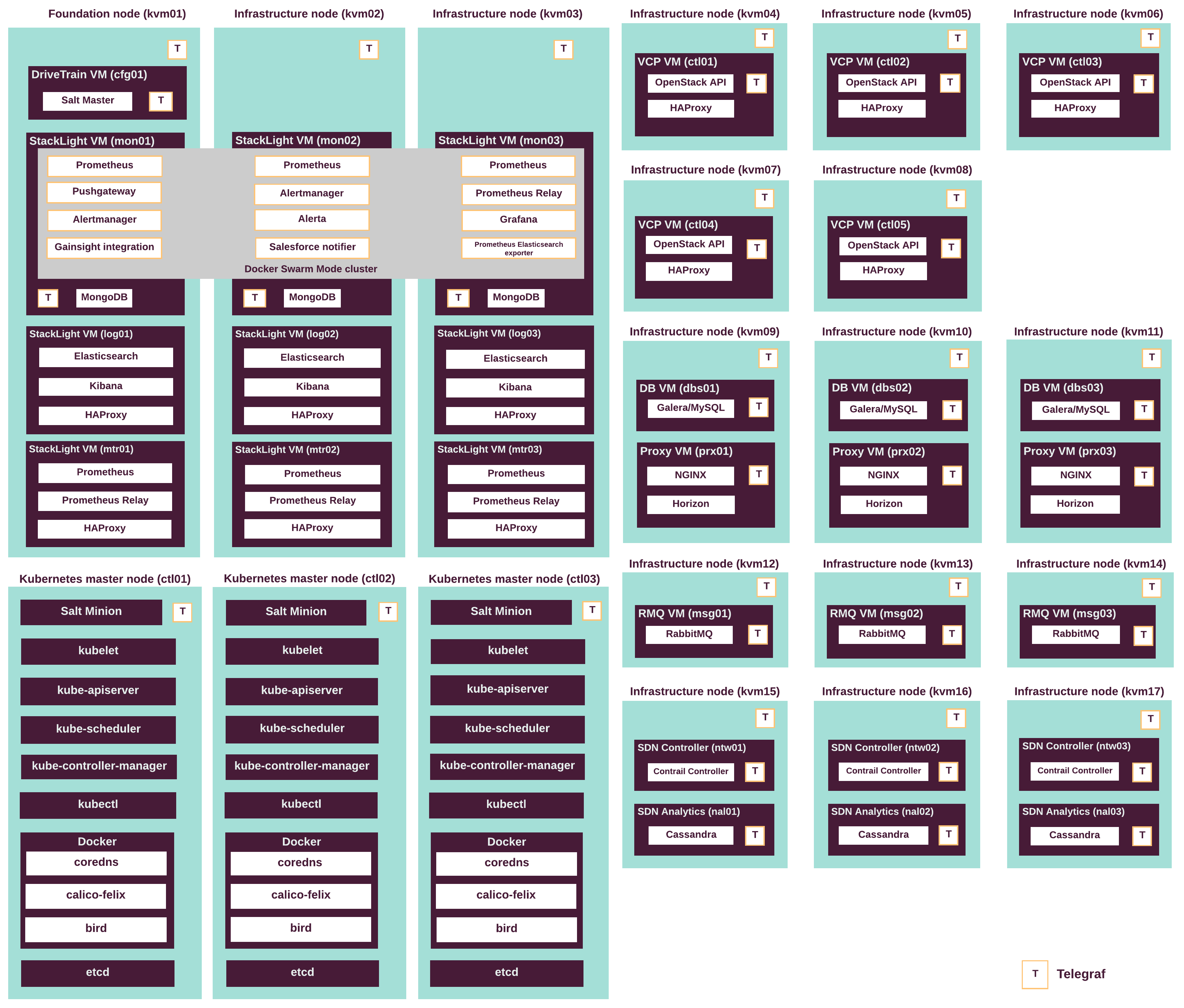
각 노드, VM에 Telegraf가 위치한 것을 확인 할 수 있음
Telegraf로 수집된 정보는 Prometheus에 직접 전달되거나 Pushgateway를 통해 전달

AFD : Anomaly and Fault Detection
GSE : Global Status Evaluation
Sensu : Monitoring pipeline
Uchiwa : Sensu dashboard
Redis : OpenStack에서의 cache, Metric collector의 보조적인 역할

Telemter의 Tool Chain

Prometheus의 Push Client를 구현
Telemeter server는 Prometheus에게 Push 방식으로 메트릭을 제공, 메트릭에 대한 안전성 검사
Telemeter client는 아래 차이점에서 등장하는 Prometheus endpoint를 통해 메트릭을 수집
- 해당 특징 때문에 prometheus federation에 종속성을 가짐

위 코드에서 --to=https://a0283e21221174397aaa38f2f16a8b71-1711060242.ap-northeast-2.elb.amazonaws.com는 management의 Telemeter server 로드밸런서

Telemeter를 쓴 이유는 자동화된 연결을 지원하기 위함으로 보임
Federation을 사용할 경우 management에 있는 prometheus에게 pulling 하기 위한 endpoint를 적어야 함
그러나 Push 방식인 Telemeter를 사용할 경우 특정 로드 밸런서의 endpoint를 받아와서 적용한 것으로 추가적인 클러스터나 노드 ( MCC에선 머신 ) 가 생겼을 때 연결하기 더 용이
여러 Federation 방식

Thanos - 사이드카의 형태로 Prometheus에 붙혀 메트릭 수집

Prometheus federation - Prometheus의 서비스를 기반으로 연결하여 정보를 수집
Clustering이 안된다는 단점이 존재

Prometheus는 Pull 방식으로 메트릭 수집
Pulling하기 위한 엔드포인트를 exporter로 메트릭 수집 후 노출
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'Prometheus federation은 Pulling하기 위한 엔드포인트를 Prometheus 자체에 생성하여 구현
- endpoint는 http://‘target URL’/federate

Prometheus에는 /federate 경로를 통해 param에 해당하는 메트릭을 노출
params는 필터링 기능을 담당
기본적으로 소개되는 유형으로는 다음과 같음
Hierarchical federation

Cross-service federation

Regional Cluster의 Telemeter client는 Proxy를 통해 Management Cluster로 송신
Managed Cluster는 Direct access 되었기 때문에 Proxy를 없이 Regional Cluster로 송신
# The server's part of the Telemeter definition.
telemeterServer:
enabled: false
# Logging verbosity.
verbose: false
# Telemeter Server whitelist.
whitelist:
- '{__name__=~"telemetry:.+"}' # The client's part of the Telemeter definition.
telemeterClient:
enabled: false
# Telemeter server URL, accessible from the client.
to: "ADD_ADDRESS_HERE"
# Metrics federation interval.
interval: 4m
# Token of the Service Account defined in the "id" field that is taken
# from the .name Secret object if .value is not specified.
token:
name: "telemeter-token"
value: ""
Telegraf

Telegraf : 메트릭 콜렉터
InfluxDB : 메트릭을 저장하는 시계열 DB
Chronograf : InfluxDB의 시각화 플랫폼
Kapacitor : 경고와 이상 감지를 수행하는 데이터 처리 엔진
Plugin
- Input : 대상으로 부터 데이터를 수집
- Output : 수집된 데이터를 메트릭의 형태로 제공받는 대상
- Processor : 통과하는 데이터에 가공 처리하여tag추가, 필드 변경, timestamp 추가 등 송신
- Aggregator : 실행 평균, 표준 편차등의 Input에서 수집된 데이터 외의 메트릭을 생성해서 송신
- period 기준, 일정 시간 내의 메트릭의 행동에 대한 데이터를 취급
Plugin directory | Telegraf 1.22 Documentation (influxdata.com)
Plugin directory | Telegraf Documentation
Thank you for your feedback! Let us know what we can do better:
docs.influxdata.com


플러그인 디렉토리에서 지원하는 플러그인을 확인할 수 있음
이 중 Input, Output의 핵심 키워드로 Agent가 있으며 해당 플러그인에서 수집, 송출을 담당
MCP에서는 Node, VM단위로 배포되어 활동하지만 MCC는 클러스터 단위로 배포
Input 플러그인은 대상이 되는 플랫폼의 데이터 필드를 맞춰 정보를 수집
Output 플러그인은 대상이 되는 플랫폼의 데이터 필드로 데이터를 가공해 송출

플러그인에 대한 종류로 나뉘어 각 폴더는 종류별로 지원하는 포맷을 제공

버전에 따른 차이가 있을 경우 아래와 같이 다른 포맷을 제공
fields["status_code"] = mapHealthStatusToCode(kibanaStatus.Status.Overall.State)
fields["concurrent_connections"] = kibanaStatus.Metrics.ConcurrentConnections
fields["response_time_avg_ms"] = kibanaStatus.Metrics.ResponseTimes.AvgInMillis
fields["response_time_max_ms"] = kibanaStatus.Metrics.ResponseTimes.MaxInMillis
fields["requests_per_sec"] = float64(kibanaStatus.Metrics.Requests.Total) / float64(kibanaStatus.Metrics.CollectionIntervalInMilles) * 1000
versionArray := strings.Split(kibanaStatus.Version.Number, ".")
arrayElement := 1
if len(versionArray) > 1 {
arrayElement = 2
}
versionNumber, err := strconv.ParseFloat(strings.Join(versionArray[:arrayElement], "."), 64)
if err != nil {
return err
}
// Same value will be assigned to both the metrics [heap_max_bytes and heap_total_bytes ]
// Which keeps the code backward compatible
if versionNumber >= 6.4 {
fields["uptime_ms"] = int64(kibanaStatus.Metrics.Process.UptimeInMillis)
fields["heap_max_bytes"] = kibanaStatus.Metrics.Process.Memory.Heap.TotalInBytes
fields["heap_total_bytes"] = kibanaStatus.Metrics.Process.Memory.Heap.TotalInBytes
fields["heap_used_bytes"] = kibanaStatus.Metrics.Process.Memory.Heap.UsedInBytes
fields["heap_size_limit"] = kibanaStatus.Metrics.Process.Memory.Heap.SizeLimit
} else {
fields["uptime_ms"] = int64(kibanaStatus.Metrics.UptimeInMillis)
fields["heap_max_bytes"] = kibanaStatus.Metrics.Process.Mem.HeapMaxInBytes
fields["heap_total_bytes"] = kibanaStatus.Metrics.Process.Mem.HeapMaxInBytes
fields["heap_used_bytes"] = kibanaStatus.Metrics.Process.Mem.HeapUsedInBytes
}추후 생성되는 변경점은 릴리즈를 업데이트하며 대응

새로운 plugin이 필요할 경우 해당 업데이트를 진행

변경점이 있을경우 해당 업데이트 진행

추가 필드가 필요한 경우도 해당
2.16.0 버전부터 Elasticsearch 관련 데이터를 Opensearch으로 변경하는데 최신 버전의 telagraf의 목록에는 존재하지 않음
- 검색 결과 Opensearch를 대상으로하는 Prometheus Exporter가 존재
- 사용 방법은 추가 조사가 필요하지만 External plugin을 통해 구현이 가능한 것으로 확인
Authentication
StackLight는 기본적으로 5개의 web UI를 제공
- Prometheus
- Alertmanager
- Alerta
- Kibana1.26.0 버전 이후로는 Opensearch dashboard
- Grafana
해당 UI들은 keyclock 기반의 IAM에 따라 보호
IAM과 직접 통합되는 Alerta를 제외하면 모든 web UI는 proxy를 통해 IAM에 노출

Alerta를 제외한 WEB UI의 인증 과정
- StackLight web UI ( Prometheus, Grafana etc ) 의 public IP 접속
- Public IP는 Proxy를 통해 K8s LoadBalancer로 배치되어 web UI를 보호
- LoadBalancer로 HTTP 요청을 X-Forwarded-Proto나 X-Forwared-Host 헤더로 지정된 K8s internal IAM Proxy service endpoint로 라우팅
- IAM Proxy로 Keycloak 렐름에 연결해 Keycloak 로그인 폼으로 ID,PW를 입력
- Keycloack은 ID와 PW를 비교 확인
- 사용자는 해당 web UI( IAM Proxy 구성의 upstream field )에 액세스

IAM과 통합된 Alerta의 인증 과정
- Alerta web UI의 public IP 접속
- Public IP는 K8s LoadBalancer 유형으로 배포된 Alerta에 배치
- LoadBalancer로 HTTP 요청을 K8s internal Alerta service endpoint로 라우팅
- IAM 영역 내의 Alerta와 Keycloak 연결해 Keycloak 로그인 폼으로 ID,PW를 입력
- Keycloack은 ID와 PW를 비교 확인
- 사용자는 해당 web UI에 액세스
StackLight proxy
외부 액세스가 필요한 StackLight component는 MCC cluster용으로 구성된 것과 동일한 Proxy를 사용
따라서 Proxy는 management, regional, managed cluster를 배포하는 동안에만 구성 ( 이미 있는 것을 사용하기 때문에 배포 후 연결 되었다면 필요없는 것인가?? )
Proxy는 HTTP, HTTPS 트래픽 처리